In 2005, I analyzed the transcripts of players at a public exhibition of my IF Whom the Telling Changed. This analysis helped shape my thoughts on IF interfaces as I was starting work on my next major project, Blue Lacuna, designed to reduce the number of commands rejected by the parser. This fall, Lacuna was exhibited in a similar venue: I decided to record a new set of transcripts and see if I'd managed to improve things.
Takeaways for the impatient:
Blue Lacuna was exhibited at IndieCade 2010, in a similar venue to Telling: an exhibition space filled with many other louder and more colorful games. The audience was significantly different: Telling showed at Slamdance, which is primarily a film festival, while Lacuna appeared at IndieCade, a festival entirely for games. Both events were open to the public, so there were a large number of "people off the street" without strong game affiliations in both cases.


Lacuna, like Telling, was very different from the other games at the festival: although some were slower-paced, on the whole the vibe was towards arcade games and platformers. Lacuna's venue was a mixed bag, featuring both several other slow-paced games as well as the stampede-and-shouting-inducing crowd favorite B.U.T.T.O.N.
Also like Telling, Lacuna differs from traditional IF. It uses a keyword-based interface on top of traditional IF commands. It begins with a tightly focused opening scene followed by an integrated tutorial. It immediately asks you to make introspective decisions. For these and other reasons, the data here many not be applicable to more traditional IF. (Telling used keywords also, but in a much more limited fashion; it also involved introspective decisions from the get go, and although it didn't have a tutorial there was a certain amount of hand-holding in the early moves.)
When Telling was exhibited, I was frustrated by how easy it was for people to get distracted by sounds of other games and conversation in the venue space. It's hard to read in such an environment. For Lacuna's IndieCade exhibition, I devised a special version of the game that featured background ambient audio for Chapter One (the only portion of the game likely to be reached). Headphones were displayed and several prominent messages, both on-screen and adjacent to the computer, urged people to put them on before beginning. I rarely saw players disobey this instruction.
The game ran in a Gargoyle interpreter with customized colors and fonts. The printed instructions (link) were simpler than Telling's: "Put on the headphones. Type RESTART to begin the story. When you see the > prompt, type single colored keywords to interact."
139 transcripts representing 3,125 individual commands (and here sorted by frequency) were collected, nearly twice as many as in the Telling analysis. The transcripts were automatically logged to the exhibition computer's hard drive and collected after it closed. This is dirty data: there's no way to tell whether each unique player typed RESTART to begin a new game, whether certain players played multiple times, or which if any transcripts represent festival volunteers verifying that the game was running correctly. (Anecdotally, though, people always seemed to RESTART when beginning a session, and I never saw the same person play multiple times.)
As with the earlier analysis, I hand-counted and categorized errors according to my own idiosyncratic and unscientific schema. (In fact, if it's not clear, this entire thing is very unscientific. I wouldn't stake my life or reputation on any of these results, so consider them merely quantitatively-assisted anecdotes. That said, here's some Excel love.)
Before comparing the two data sets, I want to look at a baseline assumption. The implicit goal of many of Lacuna's interface experiments was to reduce the number of parser errors seen by a player. But why is this a goal worth pursuing? My gut feeling is that people don't like being misunderstood by a computer. The higher the percentage of rejected commands in a session, the more frustrated the player will feel, the more distracted they'll be from the story, and the more likely they are to quit on a sour note and not return, either to the work in particular or IF in general. Is there any data to support this?
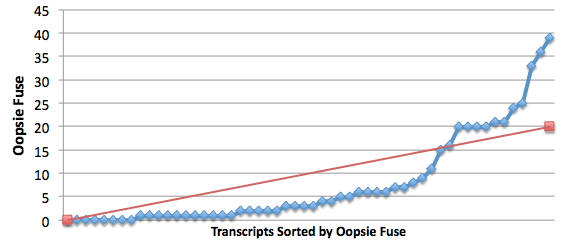
Lacuna's transcripts revealed that about 1 in 20 commands were misunderstood by the parser. Let's imagine a number called the oopsie fuse, which represents the number of moves between the final rejected input and the end of a session. If the player quits immediately after seeing an error, the oopsie fuse is 0; if they play for five more turns before stopping, it's 5. With a 1 in 20 chance that any single input will be rejected, over a large number of transcripts we should expect a median oopsie fuse of 10. If it's significantly less than 10, however, it could indicate that seeing an error makes one more likely to stop playing.
In fact, this is just what we find. In the Lacuna transcripts, the median oopsie fuse is 3, not 10: that is, in half of all transcripts with rejected inputs, the final error showed up during the last three moves of play. The graph shows oopsie fuses (sorted low to high) in blue; the red line shows the trend line these should be following if errors had no effect on quitting.
Having a command rejected does indeed seem to increase the odds that a player will stop playing. We still don't know whether they're leaving with a good or bad impression, or what effect play time has on appreciation of a piece, but at least we're not grasping totally at straws by trying to minimize rejected commands.
On average, IndieCade players spent 22 moves interacting with Blue Lacuna. This compares to an average of 36 moves for Telling.
If Lacuna's interface changes made the game more enjoyable to play, shouldn't we expect a higher average, not a lower one? This might be a result of differences in the audiences at either venue, or the interest level in the two stories.
However, if we look for a data-driven explanation, we might notice that Lacuna is a much wordier game than Telling. In a random sampling of Telling transcripts, the first ten moves corresponded to about 625 words of text; a similar sampling of Lacuna transcripts, however, showed the first ten moves taking up about 1500 words, almost two and a half times more. If Lacuna's text was broken up by inputs at the same frequency as Telling's, we might expect players to make it through 53 moves, rather than 22. Another way of saying this is that the average Lacuna player read about 1.5 times as much text as the average Telling player, meaning they were probably spending 50% more time engaging with the piece.
(The frequency of interaction points might also affect a player's willingness to spend time with a work. If Lacuna's text had in fact been broken up by more chances to type commands, would that have increased or decreased the average play time? Future work ahoy.)
Following the same system used for the Telling data, I identified and categorized 158 rejected commands in the Lacuna transcripts. The full explanation of the categories and what counts as an error can be found in the earlier report, but in brief, I consider a command as rejected any time the parser fails to understand the player's intent. If the player is told that oranges are present, types EXAMINE ORANGE or EXAMINE ORNGES or VIEW ORANGES and does not receive the desired description, that's a rejected command. If the story hadn't mentioned oranges in this location and the player fruitlessly types EXAMINE ORANGES, that wouldn't count as a reject for my purposes: it may be frustrating to the player, but the parser has successfully understood the player and returned a logical response.
In the Telling transcripts, 247 out of 2500 commands, or about 10%, were rejected. The Lacuna transcripts had only half as many rejects: 162 out of 3125, or 5%. We might guess that a certain percentage of this improvement is due to a greater reliance on keywords rather than verb-noun combinations. We can get more specifics by looking at the categorizations.
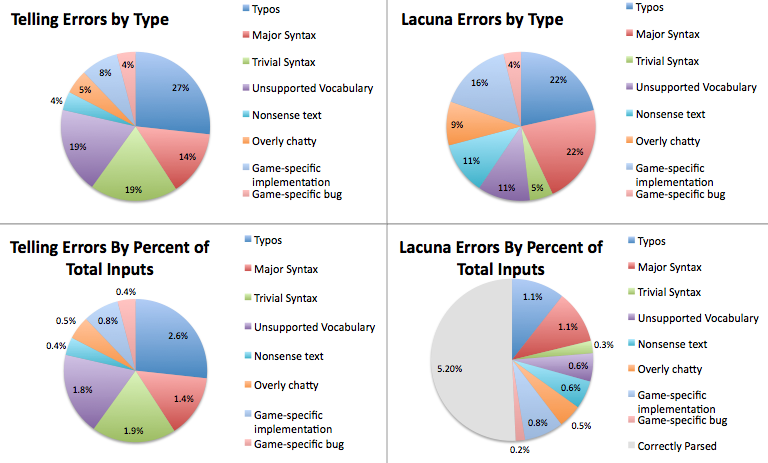
The top two pie charts break down errors for both games by type, where the full pie is the total number of rejected inputs. This is a little misleading since it doesn't show that Lacuna is doing twice as good a job: the bottom two charts show the percentage of total inputs each error category represents, with the whole pie now indicating the most error-riddled 10% of player commands. (You'll notice this makes the two Telling pies proportionally the same, but squeezes Lacuna's second pie in half.)
Looking at the bottom pair, we can see that Lacuna drastically cuts certain types of rejects as a percentage of total commands, while not having as much of an effect on others. Let's break down the interesting differences.
The most dramatic change is the reduction in commands rejected for trivial syntax errors, such as LOOK ORANGE instead of LOOK AT ORANGE: this fell from 1.9% of all inputs to only 0.3%. Keywords, of course, do an end-run around syntax problems, but reviewing the transcripts shows that the Smarter Parser extension also helps out here. (Since Lacuna's release, the Inform 7 standard rules have also been modified to catch some common syntax problems, including the example above; the Extended Grammar extension provides a large number of additional grammar lines to help further address this failing.)
Lacuna also rejected a significantly smaller number of typos (ORANEG instead of ORANGE): 1.1% vs 2.6%. This is mostly due to the Poor Man's Mistype extension, which can detect simple spelling errors where the first three letters of the misspelled word match something in scope. A review of the transcripts shows that while this extension is indeed fixing more than half of player typos, there remain many kinds of typing mistake it's not sophisticated enough to catch. Inform 7 is still very much in need of an updated version of I6's Mistype.h to provide for better spelling correction, since typos still account for nearly a quarter of all misunderstood input.
The use of keywords probably also explains the significant reduction in problems with unsupported vocabulary (down from 1.8% of all inputs to 0.6%), which includes attempts to use unimplemented synonyms for valid verbs and nouns.
Nonsense text, overly chatty responses, and implementation problems remain at about the same proportional levels. (The implementation category in Lacuna includes attempts to use keywords for non-implemented objects; Lacuna's style of making non-highlighted objects still sometimes interactable is perhaps a poor interface decision.)
Major syntax errors (players trying to interact in non-supported ways, like CLAP HANDS or using objects together) are now a proportionally larger percentage of misunderstood input, possibly because keywords meant players did not get as familiarized with the available verbs and canonized modes of interaction. (This problem is also significantly harder to patch with an extension, since it strays into the dangerously slippery slopes of true natural language processing.)
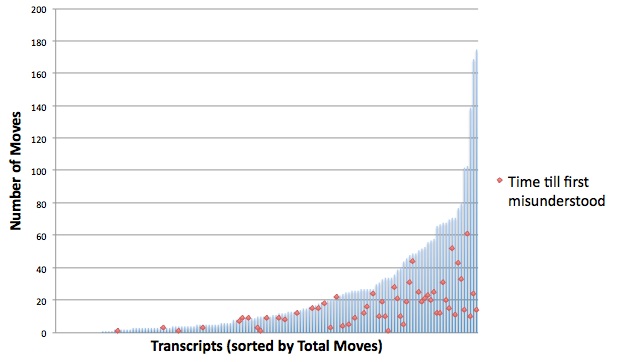
The average number of moves from the start of a transcript until the first misunderstood input was 16, almost exactly double the 7.9 observed in the Telling data (and corresponding satisfyingly with the halved frequency of errors). All text blocks being equal, players are going twice as long without seeing an error as they were in Telling, and only in a very small minority of cases is the first response now an error message.
Since Lacuna begins by asking the player to choose a gender, we can try breaking down this data into male-identified and female-identified sets to see if any interesting patterns emerge.
| Transcripts | Average Total Turn Count | Errors | Average Turns Till First Misunderstood | |
|---|---|---|---|---|
| Female-identified | 31 | 24 | 4.6% | 19 |
| Male-identified | 108 | 22 | 5.4% | 16 |
On the whole, the results are similar and probably not statistically significant. There may be a slight trend for female-identified players to play longer, encounter fewer errors, and go longer before encountering their first error. This is the sort of thing it would be great to turn real scientists loose on.
In the Telling transcripts, I observed that players would often press enter without typing anything when they seemed stuck. In Lacuna, I arranged for this behavior to behave as if LOOK had been entered, and explicitly introduced it in the tutorial. This seems to be an extremely popular feature: I would guess something like 5% of all inputs in the sample set were blank lines, with players seemingly making frequent use of this easy way to reestablish their orientation in the environment.
One category of misunderstood inputs that's been mostly ignored by parsers and parser-improving extensions to date is IM or SMS lingo. Players in the Lacuna transcripts occasionally type things like "lol," "whoa," or "hi." Texting has now become the most common text-based communication method for a significant percentage of the population, so it's only natural for players to try to communicate in a familiar dialect. Standard IF parsers have long acknowledged a player's tendency to be chatty in their responses to inputs like YES ("That was a rhetorical question.") It might be interesting to write an extension that looks for chat-like lingo, and attempts to respond in some fashion, perhaps acknowledging the reference and directing the player towards the expected input.
It would be interesting to look at an entirely keywords-based game to see if time spent playing was different when the possibility of errors is eliminated entirely. Does interaction increase or decrease the amount of text players are willing to read?
I'm looking only at parser errors here, but it might be interesting to do similar work based on unimplemented responses. Does getting a message like "You see nothing unexpected" have similar deleterious effects on how long a player will spend with a game as a flat out error like "I don't understand the word 'view.'"? In general, should work on making more accessible IF focus more on improving the parser, or improving the detail of the stories?
{kind=link}